
Create amazing PowerPoint slides using R - Getting the data
###Part 2 (3)
Now that we have a few basic tools for manipulating PowerPoint slides (Part 1), let’s scrape the data we need to create Mr. Eastwood’s filmography slide. We’ll get the data from IMDB, doing in R what S Anand has done in Python. In Part 3, we will use this data for constructing a PowerPoint slide with lots (needless, but educational) animation, and interaction.
Code with the “>” prompt should be entered in the R console.
Let’s get started.
Setup
We’ll use the same R/RStudio setup and the packages we loaded in Part 1.
We will need some Hadley Wickham voodoo for web scraping and data manipulation.
1 - rvest Web scraping simplified.
2 - stringr String manipulation simplified.
3 - plyr Apply simplified.
4 - dlyr Data manipulation simplified.
Scraping data using rvest
We will do two things in this post:
1 - Get a list of films that Mr. Eastwood has acted in.
2 - Get the poster images for each of the films.
We want to put Clint Eastwood’s filmography as an actor on a PowerPoint slide, using R, without as much as a point or a click. But we will have to click through to IMDB to get the lowdown on all the movies Mr. Eastwood has starred in. Searching for Mr. Eastwood’s name get us to his filmography page. We want to create a data frame with the following data from this page:
- Film Title.
- Release Year.
- URL to the film’s page on IMDB (we’ll need this to get the film’s poster image).
We will work on a locally saved copy of the page. In Chrome, go the menu > Save page as... and save to an appropriate location. To understand the elements we need to extract, we need the SelectorGadget. This nifty little tool help’s identify the CSS selectors we can use to get the data we want from a web-site. And rvest makes great use of the output. You can get the Chrome extension, or a bookmarklet.
Navigate to Mr. Eastwood’s IMDB page. The filmography includes movies and programs where Mr. Eastwood has participated in, not necessarily as an actor. Since we want to be able to select films in which Mr. Eastwood has performed as an actor, we need to open up one of the other sections of the filmography to be able to deselect the other sections. 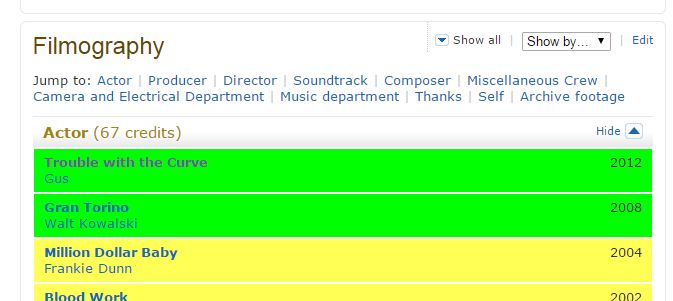
I used the Archive footage section. Now start SelectorGadget. Let’s select the films from the Actor section. This selects alternate films. Click again on an unhighted film to select the other entries. This of course selects all the films the Mr. Eastwood was involved, not only those as an actor. Scroll down to the Archive footage section and select one of the programs. This will deselect all the items in that section, leaving us with just the elements from the Actor section. We can copy the identified CSS selectors, and paste in the R code.
Now in R:
# Load these packages
install.packages(c("rvest","stringr","plyr"))
library(rvest)
library(stringr)
library(plyr)
# Mr. Eastwood's IMDB page
clint_url <- "http://www.imdb.com/name/nm0000142/"
local_html <- "C://path_to_page//Clint Eastwood - IMDB.html"
# These are the elements that contain film information that we are interested in
film_selector <- "#filmo-head-actor+ .filmo-category-section .filmo-row"
# Parse the html page
clint_page <- html(local_html)
# Now select the films
filmography <- clint_page %>% html_nodes(film_selector)
# Check
> length(filmography)
[1] 67
# Look at the first and last elements of the extracted nodes
> filmography[[1]]
<div class="filmo-row odd" id="actor-tt2083383">
<span class="year_column">
2012
</span>
<b><a href="/title/tt2083383/?ref_=nm_flmg_act_1">Trouble with the Curve</a></b>
<br/><a href="/character/ch0335867/?ref_=nm_flmg_act_1">Gus</a>
</div>
> filmography[[67]]
<div class="filmo-row odd" id="actor-tt0048554">
<span class="year_column">
1955
</span>
<b><a href="/title/tt0048554/?ref_=nm_flmg_act_67">Revenge of the Creature</a></b>
<br/>
Jennings
(uncredited)
</div>
We have 67 films and the first and last films match. You can see a number of TV appearances. Let’s remove those.
filmography <- filmography[-grep("TV Movie|TV Series",html_text(filmography))]
# Check the number of movies
> length(filmography)
[1] 60
We now have the movies, but there is more to do. We want to get the title and year. Let’s look at one film node to understand how.
> filmography[[1]]
<div class="filmo-row odd" id="actor-tt2083383">
<span class="year_column">
2012
</span>
<b><a href="/title/tt2083383/?ref_=nm_flmg_act_1">Trouble with the Curve</a></b>
<br/><a href="/character/ch0335867/?ref_=nm_flmg_act_1">Gus</a>
</div>
The film year is in a span element. The title is an a element and there’s a link in the a element that will take us to the film’s page on IMDB.
Let’s create a dataframe with all the elements.
films <- NULL
films$year <- filmography %>% html_nodes("span") %>% html_text() %>% str_trim()
films$title <- filmography %>% html_nodes("b a") %>% html_text()
films$url <- paste0("http://www.imdb.com",filmography %>% html_nodes("b a") %>% html_attr("href"))
films <- as.data.frame(films)
This give us a data frame with what we’re interested in, but I’d like to try to get the character names as well. The problem is that they’re not in the same location for every film. In the example above, it’s under the second a element. In the example below, that’s not the case.
> filmography[[60]]
<div class="filmo-row odd" id="actor-tt0048554">
<span class="year_column">
1955
</span>
<b><a href="/title/tt0048554/?ref_=nm_flmg_act_67">Revenge of the Monsters</a></b>
<br/>
Jennings
(uncredited)
</div>
I couldn’t come up with a CSS selector that works for both cases, so we’ll have to deal with it film by film. We’ll use the daply function in plyr to go through the data frame film by film, and add the character name.
# Preserve the film sequence in the data frame, and use for sorting and naming the images
films$index <- sprintf("%02d",seq_along(1:length(films$year)))
# We need a function that we can use with daply, that extracts the character name from the filmography nodes, and handles _uncredited_ entries
get_character <- function(film,filmography) {
i <- as.integer(film$index)
character_name <- filmography[i] %>% html_nodes(xpath=".//a[2]") %>% html_text()
if (length(character_name)==0) {
character_name <- filmography[[i]] %>%
html_nodes(xpath="text()[preceding-sibling::br]") %>%
html_text() %>%
str_trim() %>%
str_replace("\n"," ")
}
return(character_name)
}
# Now, let's add the character names to the data frame
films$character_name <- daply(films,.(index),get_character,filmography)
Now, the poster images. We’ll name these based on the sequence the data is in (by release year), and add the name of the file to our data frame.
# Create a sub-directory for the images.
> if (!file.exists("img")) { dir.create("img") }
# Create an image file name for each film in the data frame
> films$img_file <- paste0("img/img",films$index,".jpg")
# Loop through the films, get the posters and save to the img directory, using the file names just assigned. If no poster is found, then we'll handle it manually.
for (i in 1:nrow(films)) {
img_node <- html(films$url[i] %>%
html_nodes(xpath='//td[@id="img_primary"]//img')
if (length(img_node)==0) {
films$img_file[i] <- "img/img00.jpg"
cat(i," : img file NOT FOUND: ",films$img_file[i],"\n")
}
else {
img_link <- html_attr(img_node,"src")
cat(i," :",films$img_file[i]," : ",img_link,"\n")
download.file(img_link,films$img_file[i],method="internal",mode="wb")
}
}
# Check which of the files were not found and download them manually
>which(film$img_file=="img/img00.jpg")
[1] 52 54 55
> films$title[which(films$img_file=="img/img0000.jpg")]
[1] "Escapade in Japan" "The First Traveling Saleslady" "Star in the Dust"
These films don’t have any associated posters. Find a jpg image for each, and save to the img directory. Rename the files according to the naming scheme. And set the correct file name in the data frame
# These images don't exist. Download manually, rename and save with the appropriate name in the img directory
films[52,"img_file"] <- "img/img52.jpg"
films[55,"img_file"] <- "img/img55.jpg"
films[54,"img_file"] <- "img/img54.jpg"
# Correct this title (appears with strange characters because of my locale, I assume)
films[40,"title"] <- "Kelly's Heroes"
# Save the data frame in a tab separated file
write.table(films,file="eastwood_films.csv",append=FALSE,quote=TRUE,sep="\t",row.names=FALSE)
More web scraping
I got some additional data on the box office receipts of Mr. Eastwood’s films from Box Office Mojo. The code and reulting data frame is available on Github
That required some work! But we now have the poster images and some basic data. (And I know so much more about web scraping than before!)
Next up:
Part 3 - About time! We’ll use the data to play around with more advanced animation and interaction in PowerPoint.
Previously: Part 1 - RDCOMClient basics